Judea Pearl is one of the most important scholars in the field of causal reasoning. His book Causality is the leading textbook in the field.
This blog has two short parts — a paper he wrote a few months ago and an interview he gave a few days ago.
*
He recently wrote a very interesting (to the very limited extent I understand it) short paper about the limits of state-of-the-art AI systems using ‘deep learning’ neural networks — such as the AlphaGo system which recently conquered the game of GO and AlphaZero which blew past centuries of human knowledge of chess in 24 hours — and how these systems could be improved.
The human ability to interrogate stored representations of their environment with counter-factual questions is fundamental and, for now, absent in machines. (All bold added my me.)
‘If we examine the information that drives machine learning today, we find that it is almost entirely statistical. In other words, learning machines improve their performance by optimizing parameters over a stream of sensory inputs received from the environment. It is a slow process, analogous in many respects to the evolutionary survival-of-the-fittest process that explains how species like eagles and snakes have developed superb vision systems over millions of years. It cannot explain however the super-evolutionary process that enabled humans to build eyeglasses and telescopes over barely one thousand years. What humans possessed that other species lacked was a mental representation, a blue-print of their environment which they could manipulate at will to imagine alternative hypothetical environments for planning and learning…
‘[T]he decisive ingredient that gave our homo sapiens ancestors the ability to achieve global dominion, about 40,000 years ago, was their ability to sketch and store a representation of their environment, interrogate that representation, distort it by mental acts of imagination and finally answer “What if?” kind of questions. Examples are interventional questions: “What if I act?” and retrospective or explanatory questions: “What if I had acted differently?” No learning machine in operation today can answer such questions about actions not taken before. Moreover, most learning machines today do not utilize a representation from which such questions can be answered.
‘We postulate that the major impediment to achieving accelerated learning speeds as well as human level performance can be overcome by removing these barriers and equipping learning machines with causal reasoning tools. This postulate would have been speculative twenty years ago, prior to the mathematization of counterfactuals. Not so today. Advances in graphical and structural models have made counterfactuals computationally manageable and thus rendered meta-statistical learning worthy of serious exploration…
Figure: the ladder of causation
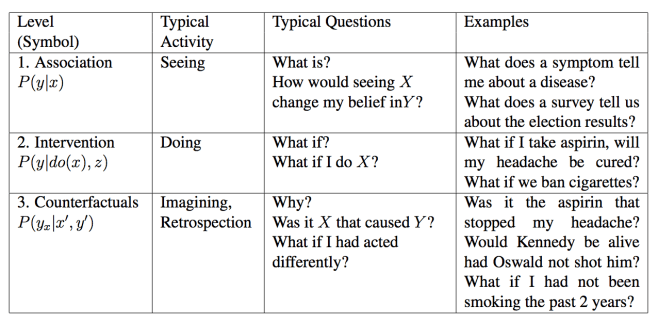
‘An extremely useful insight unveiled by the logic of causal reasoning is the existence of a sharp classification of causal information, in terms of the kind of questions that each class is capable of answering. The classification forms a 3-level hierarchy in the sense that questions at level i (i = 1, 2, 3) can only be answered if information from level j (j ≥ i) is available. [See figure]… Counterfactuals are placed at the top of the hierarchy because they subsume interventional and associational questions. If we have a model that can answer counterfactual queries, we can also answer questions about interventions and observations… The translation does not work in the opposite direction… No counterfactual question involving retrospection can be answered from purely interventional information, such as that acquired from controlled experiments; we cannot re-run an experiment on subjects who were treated with a drug and see how they behave had then not given the drug. The hierarchy is therefore directional, with the top level being the most powerful one. Counterfactuals are the building blocks of scientific thinking as well as legal and moral reasoning…
‘This hierarchy, and the formal restrictions it entails, explains why statistics-based machine learning systems are prevented from reasoning about actions, experiments and explanations. It also suggests what external information need to be provided to, or assumed by, a learning system, and in what format, in order to circumvent those restrictions…
[He describes his approach to giving machines the ability to reason in more advanced ways (‘intent-specific optimization’) than standard approaches and the success of some experiments on real problems.]
‘[T]he value of intent-base optimization … contains … the key by which counterfactual information can be extracted out of experiments. The key is to have agents who pause, deliberate, and then act, possibly contrary to their original intent. The ability to record the discrepancy between outcomes resulting from enacting one’s intent and those resulting from acting after a deliberative pause, provides the information that renders counterfactuals estimable. It is this information that enables us to cross the barrier between layer 2 and layer 3 of the causal hierarchy… Every child undergoes experiences where he/she pauses and thinks: Can I do better? If mental records are kept of those experiences, we have experimental semantic to counterfactual thinking in the form of regret sentences “I could have done better.” The practical implications of this new semantics is worth exploring.’
The paper is here: http://web.cs.ucla.edu/~kaoru/theoretical-impediments.pdf.
*
By chance this evening I came across this interview with Pearl in which he discuses some of the ideas above less formally, HERE.
‘The problems that emerged in the early 1980s were of a predictive or diagnostic nature. A doctor looks at a bunch of symptoms from a patient and wants to come up with the probability that the patient has malaria or some other disease. We wanted automatic systems, expert systems, to be able to replace the professional — whether a doctor, or an explorer for minerals, or some other kind of paid expert. So at that point I came up with the idea of doing it probabilistically.
‘Unfortunately, standard probability calculations required exponential space and exponential time. I came up with a scheme called Bayesian networks that required polynomial time and was also quite transparent.
‘[A]s soon as we developed tools that enabled machines to reason with uncertainty, I left the arena to pursue a more challenging task: reasoning with cause and effect.
‘All the machine-learning work that we see today is conducted in diagnostic mode — say, labeling objects as “cat” or “tiger.” They don’t care about intervention; they just want to recognize an object and to predict how it’s going to evolve in time.
‘I felt an apostate when I developed powerful tools for prediction and diagnosis knowing already that this is merely the tip of human intelligence. If we want machines to reason about interventions (“What if we ban cigarettes?”) and introspection (“What if I had finished high school?”), we must invoke causal models. Associations are not enough — and this is a mathematical fact, not opinion.
‘As much as I look into what’s being done with deep learning, I see they’re all stuck there on the level of associations. Curve fitting. That sounds like sacrilege, to say that all the impressive achievements of deep learning amount to just fitting a curve to data. From the point of view of the mathematical hierarchy, no matter how skillfully you manipulate the data and what you read into the data when you manipulate it, it’s still a curve-fitting exercise, albeit complex and nontrivial.
‘I’m very impressed, because we did not expect that so many problems could be solved by pure curve fitting. It turns out they can. But I’m asking about the future — what next? Can you have a robot scientist that would plan an experiment and find new answers to pending scientific questions? That’s the next step. We also want to conduct some communication with a machine that is meaningful, and meaningful means matching our intuition.
‘If a machine does not have a model of reality, you cannot expect the machine to behave intelligently in that reality. The first step, one that will take place in maybe 10 years, is that conceptual models of reality will be programmed by humans. The next step will be that machines will postulate such models on their own and will verify and refine them based on empirical evidence. That is what happened to science; we started with a geocentric model, with circles and epicycles, and ended up with a heliocentric model with its ellipses.
‘We’re going to have robots with free will, absolutely. We have to understand how to program them and what we gain out of it. For some reason, evolution has found this sensation of free will to be computationally desirable… Evidently, it serves some computational function.
‘I think the first evidence will be if robots start communicating with each other counterfactually, like “You should have done better.” If a team of robots playing soccer starts to communicate in this language, then we’ll know that they have a sensation of free will. “You should have passed me the ball — I was waiting for you and you didn’t!” “You should have” means you could have controlled whatever urges made you do what you did, and you didn’t.
[When will robots be evil?] When it appears that the robot follows the advice of some software components and not others, when the robot ignores the advice of other components that are maintaining norms of behavior that have been programmed into them or are expected to be there on the basis of past learning. And the robot stops following them.’
Please leave links to significant critiques of this paper or work that has developed the ideas in it.
If interested in the pre-history of the computer age and internet, this paper explores it.

Interesting. But can I extend it to Brexit and define a start point from which
such improvement might develop.
If you have not read the article in The Mail, Sat 19th about Felixstowe and how it handles
£80b worth of container traffic I recommend doing so (Robert Hartman was the journalist)
This provides a marvellous example of what is currently possible. And a belief that it
could be easily extended to EU and the Irish border issue. Add AI on top of that in a
few years time and one wonders what all the fuss is about – other than pure politics
both sides of the Channel.
You are probably fully aware of Felixstowe but just in case ….
Bob Poots
LikeLike
Pingback: On the referendum #31: Project Maven, procurement, lollapalooza results & nuclear/AGI safety – Dominic Cummings's Blog